01
VMG Digital · AI & Automation
Kraken
Multi-agent creative brief orchestrator. 1 orchestrator, 11 specialized sub-agents, 3 LLMs — transforming raw client briefs into structured campaign strategy.
11
Specialized agents
3
LLMs (task-matched)
1.89s
Agent latency
102
Tokens/sec throughput
Anton EliassonMarch 2026
02
The Problem
Creative briefs are broken
The recurring bottleneck in digital creative campaigns isn't production — it's what comes before it.
Incomplete inputs
Client briefs arrive missing audience specificity, competitive context, and measurable objectives. Strategists spend days manually reconstructing what should have been there.
Hidden assumptions
Briefs are full of unstated beliefs about the audience, the product, and the platform. These go unchallenged until creative is already in production.
No structured pipeline
The path from brief to creative direction relies on individual strategist judgment with no consistent analytical framework across campaigns.
Time cost
Strategists spend days manually doing work that follows repeatable analytical patterns — assumption testing, persona building, KPI structuring, competitive mapping.
03
System Architecture
Orchestrator + 11 specialized sub-agents
User Uploads PDF Brief
→
Multimodal Extraction Gemini 2.5 Flash
→
Supabase (structured)
→
User Selects brief in chat
→
Webhook + Brief ID
Orchestrator Agent
Evaluates pipeline progress. Routes to correct sub-agent. Manages session state and user conversation. Never processes brief content directly.
GPT-5.4
Autonomous
User decision point
11 sub-agents · Grok 4.1 Fast · 1.89s latency · 102 tok/s
🗃
Supabase — Shared Persistence
Source of truth for all brief data and agent outputs. Sub-agents read context and write outputs directly — bypassing the orchestrator to prevent lossy summarization.
04
Model Selection
Three models, three reasons
Each model selected for a specific capability advantage — not benchmarks.
Ingestion Layer
Gemini 2.5 Flash
Best-in-class multimodal analysis. Creative briefs arrive as designed PDFs with layouts, images, and brand assets. Gemini's visual understanding outperforms other models at parsing these into structured data. Used across multiple products for image and video analysis.
Selected for: visual parsing
Orchestration
GPT-5.4
Strong reasoning and instruction-following for routing decisions and conversational management. The orchestrator's job is lightweight — it routes, tracks state, and manages the user conversation. It never processes brief content.
Selected for: reasoning & routing
11 Sub-Agents
Grok 4.1 Fast
Most reliable tool-call execution of any model tested. Other models would skip logging steps or malform tool calls. Combined with exceptional speed, the latency compounds across 11 pipeline steps.
1.89s latency
102 tok/s
Selected for: speed + tool reliability
05
Key Design Decisions
What we learned building it
01
Modular agents, not monolithic
A single model with all 11 frameworks in one system message couldn't maintain coherence. Instructions bled across tasks. Isolating each step into its own agent with its own system message was the only way to get consistent output.
02
Database as output channel
Passing sub-agent outputs back through the orchestrator caused lossy summarization. The orchestrator would rewrite or condense details. Sub-agents now write directly to Supabase. The orchestrator only receives completion signals — never content.
03
Session persistence through state
Progress stored in the database, not in memory. Users can leave mid-process, return days later, and resume at the correct step. Users can also go back and reprocess any previous step.
04
Human-in-the-loop at creative decision points
Analytical steps (1–7) run with minimal user input. Creative divergence steps (8, 10, 11) require explicit user selection before anything is logged. Nothing is committed until the user chooses.
06
The 11-Step Pipeline
Where the system works — and where the user decides
Foundation & Audience — Autonomous
01
Assumption Logger
Surfaces explicit + implicit assumptions. Structured 6-field blocks.
Autonomous
02
Product Truth Report
16-section deep analysis. Source-backed research.
Autonomous
03
Persona Mapper
1 core persona + 2 test angles. GWI-grounded.
User reviews
04
Platform Strategist
Mobile-first playbook per platform.
Autonomous
Strategy Synthesis — Guided
05
KPI Strategist
Hard + soft KPI pairing. Confidence intervals.
User reviews
06
4Ps Summary
Product, People, Platform, Purpose. Quality gate.
Autonomous
07
FORCE Framework
Bridges strategy to creative. Insight Triangle.
Autonomous
Creative Development — User-Led
08
The 5 Whys
5 Creative North Star options. 2–8 word POVs.
User selects 1 of 5
09
Strategy Alignment
25-slide client-facing deck from all prior work.
Autonomous
10
Main Ideas
7 overarching campaign ideas. Natural language.
User selects 1 of 7
11
Creative Narratives
Mobile-first concepts per platform. Stock/MG/UGC.
User approves for production
System runs autonomously
User reviews output
User selects from options
User approves for production
User's journey through the pipeline
Upload brief
→
Steps 1–2 run
→
Review personas
→
Steps 4–7 run
→
Select North Star
→
Step 9 runs
→
Select main idea
→
Approve concepts
07
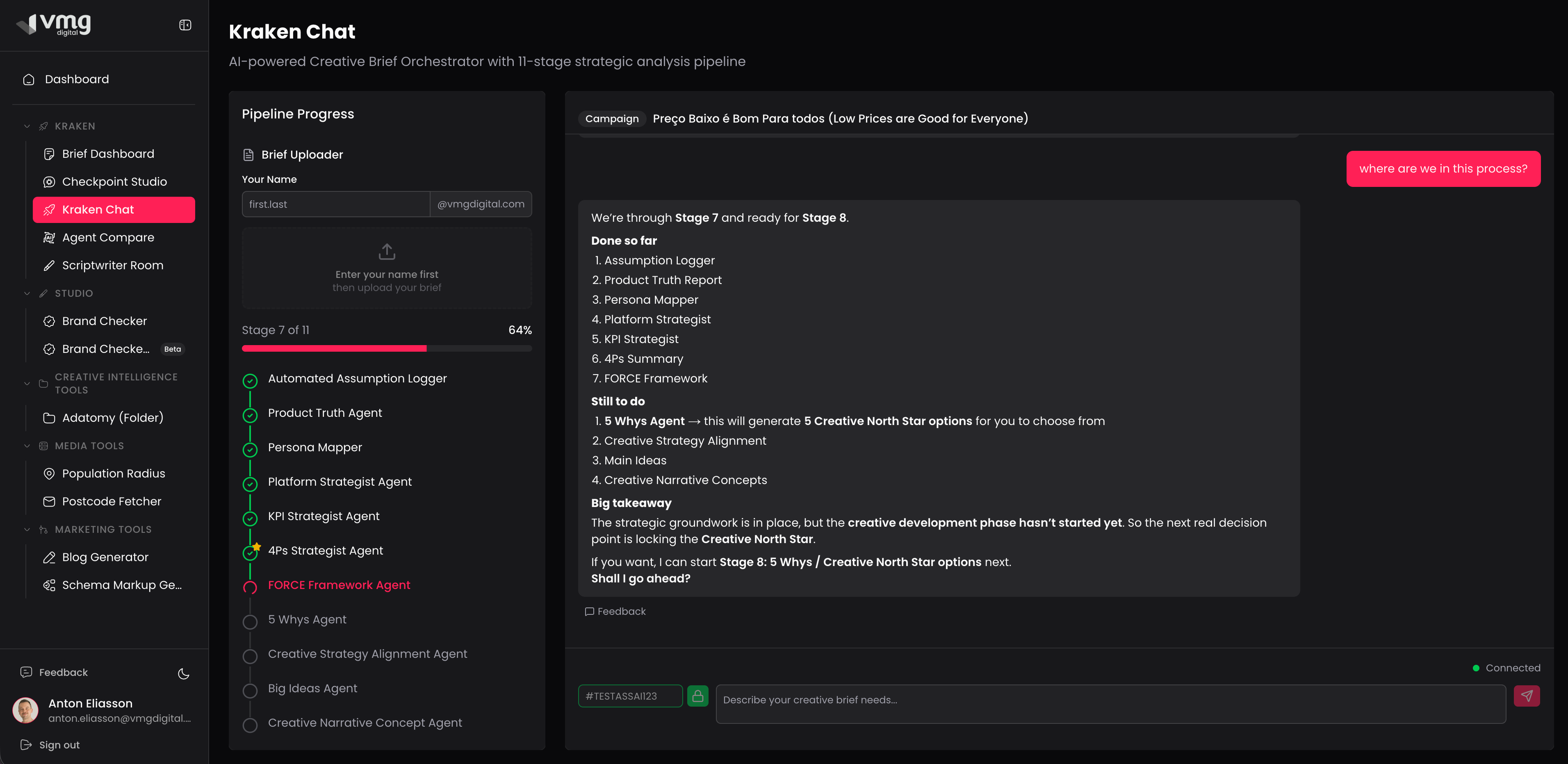
User Interface
Pipeline progress + conversational AI
Visual pipeline progress
Left sidebar shows all 11 steps with completion status. User always knows where they are in the process.
Brief selection
Users select which brief to work on. Each brief maintains independent progress through the pipeline.
Context-aware conversation
The orchestrator guides the user through each stage, explaining what's completed and what's next.
08
Looking Forward
What I'd redesign
Batch-run analytical steps
Steps 1–7 could run as a batch with minimal user input, presenting results for review rather than requiring step-by-step confirmation. The user's taste and judgment matter most from Step 8 onward.
Beyond chat UI
A dashboard view where you see all 11 steps with their outputs, click into any agent's deliverable, and have a context-aware AI sidebar. More effective than pure chat for a structured pipeline.
Automated evaluation framework
Quality assessment is currently human. At scale: automated evals — output quality scoring, consistency checks across agents, regression testing when system messages change.